
谈谈创业者的决策科学
我6月中旬在PM-Summit大会上就产品创新、决策科学和AI方面做了场分享,核心谈了谈在AI推理和因果能力日益前进的时代下,企业一把手、投资人和产品负责人如何看待创新决策科学和数据领导力。
产品创新和东西方哲学
我自己是一名老站长,05年开始做互联网,PC时代移动网时代到现在都是在一直在经历的。
在这篇文章里,我不准备谈任何具体的产品细节,也不谈任何一个公司的增长套路。
我先从一个很根源的问题谈起:关于中西方哲学的 巨大差别。这是一个产品创新和AI的大会,为什么我要谈哲学问题。
首先西方哲学的本源是要去追求知识,东方哲学根本上是追求人生。几千年前孔子跟毕达哥拉斯提出来的人生的最终极命题不一样,这也就导致了我们今天所有的企业 家决策中的巨大差别。
因为管理即决策,一种基于人生经验,另一种基于实证研究。
我长期帮助各类企业解决数据驱动和决策科学,但是我深刻的意识到一个问题:用数据驱动解决问题,本质上是回到那个终极命题:
西方哲学是求知识,人生的追求是包含在知识里面 但中国哲学求人生的答案,而知识只是其中的一个部分
那么所有的基于数据驱动决策的事情都是基于证据,叫基于证据的决策,不是基于经验决策,这是在战略管理上的重要区别。
我们今天做产品创新,最大的一个挑战就是我们怎么从假设中去避免自己陷入经验的悖论。
我们经常说我们需要迭代,需要要有创新,创新里面最大的一个问题就是我们怎么避免自我的认知偏差问题。
所以今天的这些话题里面分三块:


第一个是决策科学和数据领导力, 第二个是数据驱动和产品探索中的相关性的问题, 第三个话题就是如何建立一个科学的产品创新机制
明天会一个硅谷的专家谈的试验,下午还有ebay的团队 谈他们实验平台,我天就先把这个头开一开。
人类的决策模式
我们大脑有一种普遍的决策过程,大家在座的无论你是公司创始人、一把手,还是公司的产品经理或者一线负责产品研发的同学。
我们大脑的天然能力都差不多,都是喜欢去归纳现象,喜欢用我们的直觉去判断因果。
典型地在开会时候把老板的想法当成证明题去做,或者一把手亲自下场要证明给别人看,人类特别喜欢做判断因果 找到规律更新经验的事,这是一个需要时刻提醒自己的事情。
当然,我们有很多的这个生活经验,工作经验就是这么积累起来的,形成我们对自己判断事物的基本水平。
但是实际上呢?
Dunning Kruger效应
这个叫做Dunning Kruger效应的问题,是大卫-邓宁跟贾斯汀-克鲁格博士于1999年做的一项社会化试验。

他试验的是人类对于自身能力的评估的准确度问题,这个能力包含了逻辑思维、推理,及特别是对自己能力的上的评估。
最后评估完的一个结果很有意思,当然这是在美国啊,我们在中国是不是也有机会去做这样实验。
这个结果是这样的,三个有意思的现象:
-
32%-42%的软件工程师认为他们的技能在公司里排到百分之前五(在数学上就不可能) -
21%美国人认为他们非常可能相当有可能在未来的10年内成为百万富翁 -
于Neblaska大学教师的研究发现98%的教师认为自己的教学能力排在前25%,超过90%的人认为自己高于平均水平
这些都是严格的社会学调查结果,可想而知我们常常对自己能力的判断能力其实是失真的,但是我们却用这样的能力在判断的自己的产品,判断自己的用户。
什么叫洞察用户价值
产品的增长决策其实是非常复杂的,不过核心依然是围绕用户价值。
我先举谷歌产品例子,两个重大的产品,个是它的Chrome 还有一个是他们的adwords。
这两个产品背后的重要的洞察是什么呢?依然是用户需求。
Chrome来自于谷歌明确探索到随着网站上面加载的元素越来越多,所有的网站必然会越来越慢,必须要一代新的浏览器内核来提升网站rendering的速度,这是个技术洞察。
另一个产品Adwords的洞察也是他判断出来的用户需求。谷歌很多产品都是后发制人的。全世界最早第一代做pay per CLICK的产品的公司叫goto.com,是在97年上线的。那个时候的排序算法非常粗暴,谁的出价高,谁的排名就往上。
但是谷歌团队的观察是一定会到有一天当广告主他发现自己的广告的质量和收益低,用户端又发现广告非常烂的时候,这个系统会崩塌。
所以谷歌的团队决定研发出新的算法来解决这个广告主和广告用户之间的用户体验和收益的中长期指标平衡问题。
所以他们做出了adwords这样一个产品。
当然谷歌是遵循了科学的定性和定量研究,不断观测和优化算法,保证了在降低广告主用户点击成本的前提下还能不断优化用户的广告效果。
同理,我们一般做消费产品的,必然避免不了很多决策,包括:用户价值问题、时间特征的问题、网络效应问题和供给端的问题。
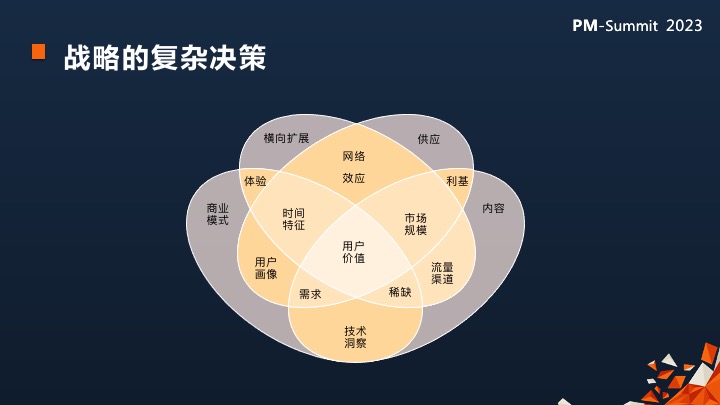
这里就要团队具备科学决策的能力。
举个例子: 用户画像的问题,特别在数据层上面是主观概率问题,比如用户端对自己的认知是什么,而不是狭隘的男或者女,要归结到功能使用及业务收入相关的指标量化评估。
如果现在大家一谈到增长模型,还是在谈AARRR,对不起,我是不认可的。
这是把问题过于简单化,AARRR你拿任何一个产品逻辑都未必套得出来。
这种被过度宣传变形的一些商业模型是不能解决根本问题的。
比较关键的方法是就是拿你的收入或你的revenue或者利润来测算你的全局变量之间的相关关系,这件事情反而才是现在所有团队应该好好做的。
我在所有我负责指导过的项目里面,都是大力推行的。
其实要找到增长的因素和数据模型,并不容易,所以 我们要学习Mark Randolph的诚实。

他作为Netflix的CEO创始人,他说过一句话就是:
顿悟其实是罕见的,但真相往往比这复杂许多。真相是,每一个好主意背后,都有上千个馊主意,两者有时很难区分
大家真的不要靠灵感,真相要复杂多,而且每一个你看到的别人的产品好策略,背后的原因你并不知道。
不要去担心大厂抄你,任何抄产品的团队并不知道这个假设的前提以及这个假设所对应的资源。
不要担心他抄你,因为他并不知道下一步你要做什么。所以你要快速的去做你的假设判断,并找到能够撬动你弯道超车的产品功能。
哪怕是看上去很大的企业,当他找不到代表机会点的特征向量的时候,其实他依然是稀里糊涂做事。
在这个年代,我觉得每个团队都应该好好的回去 建立自己的用户特征体系,并定期量化特征体系,因为每个业务是不一样的。
哪怕是阿里做网盘和中国移动做网盘,用户主要用来干什么的点都不一样,完全是不一样的。
我不认为什么所谓大厂抄你,你就完蛋,因为很多大厂团队很多这方面做的也不怎么样。
所以还是谦虚一点吧,跟Netflix的CEO去学习他的谦虚,他是不会认为自己永远是对的。
回归常态的创业与投资
事实上从整个投资上也看也对,以前的估值模式也是受到了巨大的的改变。
现在大家要谈的增长要回到本质,增长的本质是什么,就是要能挣钱,或者说你有明确的商业化的路径,你知道自己怎么挣钱,只不过现在测LTV和数据模型,但是你也要有一个自己做AB测试的一个路径。
我举一个大家都知道的公司OFO。
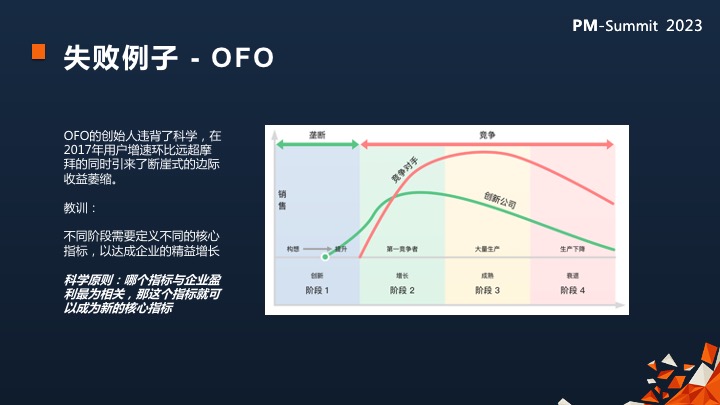
OFO就是违背科学规律的一个典型。他的早期跟摩拜在PK的时候拼命的去投单车。的确,早期的时候他通过数据可能观测到每投放多少辆车在用户端就有多少新用户进来。
在那个阶段你是可以的,但是一旦进入到了互相PK的时候, 核心观测指标其实是要重新计算的,而恰恰那个时候OFO的NPS非常差,为此他投入大量的资金去升级单车,但是边际收益一塌糊涂,这件事情就是创始团队过于自信,没有定期调整指标最后惨淡收场的教训。
所以我觉得每个团队都应该仔细分析自己产品目前处在什么阶段,以这阶段来计算自己的指标口径,以及你面向利润用户端最有可能去影响用户的行为是什么。
这才是最关键的事情。
所以我一直强调决策科学需要数据领导力。
现实情况,我看到很多企业,无论是创业企业,还是成熟企业,依然是在木桶里面干活。
在数据战略、数据文化、组织能力、流程敏捷、技术架构和数据产品等方面,存在各种短板。
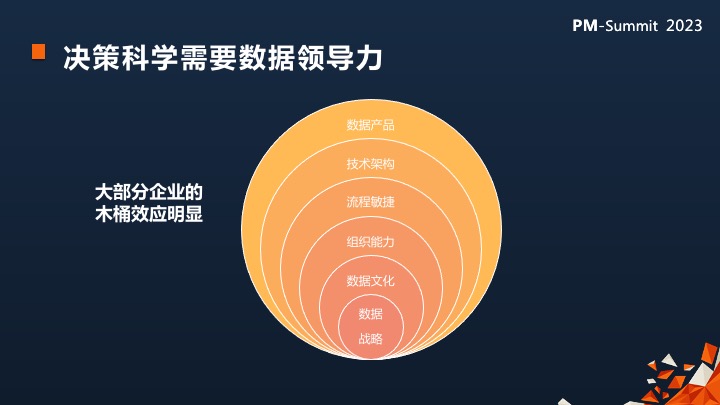
比如一个创业企业,在验证完PMF的时候,整条数据驱动决策的工作流是不是都有规划了。我不是指的买哪些软件,而是是否已经对于数仓,BI、标签和AB测试的工作流程形成了规划。
即便有些软件我现在不上,不开发,通过人工方式也可以正常做完一个数据洞察、假设验证及试验设计的过程。
不用谈什么大数据平台,AI,而是朴素地看整个企业可否拿出一个完整的数据切片,做完一次完整的全局洞察(用户行为、商品、内容、门店、业务人员动作)。
是否所有的主体特征能够科学地完成一次计算,用于决策呢?
如果不是的化,企业为什么要招那么多数据分析师呢?我相信现在还有很多团队招数据分析师天天在做报表吧?
分析师的工作不是做报表OK?可以自动化的就不要人肉了。分析师的工作是要找相关性,要去设计实验,要找到 包括数据上的的异常的波动和不同寻常的趋势。
可惜分析师这个岗位在中国已经被什么廉价化了,我们看看硅谷团队怎么干活的。
这些问题如果不是一把手亲自来建立这个文化,这个流程及组织机构,推动公司形成整个数据领导力的话,我觉得就算拥有最先进的大数据平台,还是没有解决根本问题,做不到基于证据的决策。
所以我一直替哪些被互联网平台洗脑的传统企业感到痛心,自己的业务壁垒本可以建立自己的数据战略,但却不自知。
数据驱动和产品创新
是否人在数据和AI时代就没用了吗?当然不是。
人类长处依然在创新领域,有企业家的探索精神和科学家的思维能力,直觉加上逻辑判断,就是就是探索式解决问题。所有合格的创业者都是这样在做的。
另外一方面运筹、模拟计算和数据处理是计算机的强项,这样自动化的工作通过计算机能实现。各位都是做产品做研发的,可以回去看看自己内部流程哪些可以自动化.
如果可以自动化,能否先人工验证一下这个分析洞察过程,然后工程化。
刚才有朋友问阿里的朋友:你们内部怎么评估这个需求这块产出价值比,产研需求怎么对应到这个服务器的成本和人工成本。
如果人力是一个可以伸缩的成本的话,那么那么人力投在什么功能上面或者投在什么策略上面是比较好的?
怎么评估需求对收益的这个贡献呢?
如果你采取指标量化评估的方式,就可以实现资源合理分配。
但是首先,我们要懂得统计学的基本常识。
懂点统计常识
这是一个二战中典型的例子,我相信可能大家平时做商业分析同学可能比较有感受,就是辛普森悖论这个东西在二战中就曾经误导过整个指挥官团体。
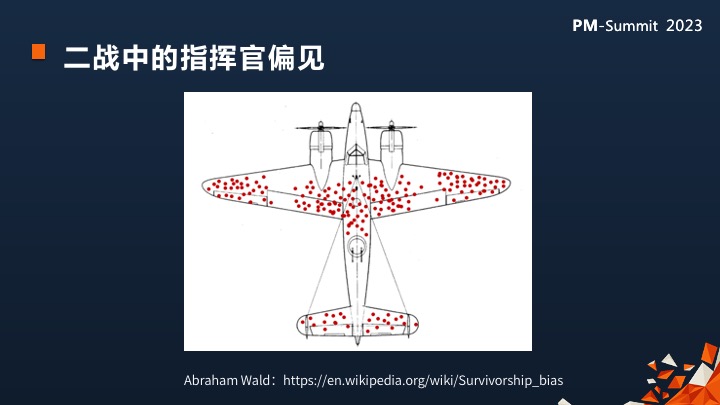
如果你去Wikipedia查Abraham Wald的这个例子的话,你就会伪阳性的害处. 因为不是真阳性,不是真的positive,而是false positive对不对?
这个例子里面的伪阳性,当时指挥官认为所有飞回来的飞机上面红点部分是被击中的部位,然后他们想改善飞机的生存率(目标),所以他们决定在这些地方给飞机加固, 但是Abraham说他们全错了。
如果我们稍微理解严格的统计概率分布的话,那另外一半没飞回来的飞机命中的区域应该大部分是非红点区。
因为统计样本少了一半,是有偏见的样本。
很多团队做AB测试,就直接随机分桶了,一些著名的头部企业还闹过业务损失的笑话,企业负责人也不专业。
这是个大错误,因为你都没有对人去进行筛选。
如果一个新的西药,只有通过了严格样本筛选下的一个双盲实验,才能上市,因为它在对照组和试验组上获得了统计功效的验证,只要看效果就可以了。
同理,在假设前提和试验结果之间,需要保证人群特征的均衡,否则试验结果肯定是不可以采信的,无论指标是否提升。在这一点上,很多看起来数据不错的产品团队要诚实一点。
但是我们为了证明自己是对的,做了很多动作,这有什么意义呢?AB测试给予的大家是一个能力,去找到真正有价值的机会,可以去自己去做假设验证设计,这是真正的数据民主化。
雷达和数据民主化

大家看这是当年发明雷达之前,我们是怎么去侦探这个飞机的,以前没有雷达就得这么干活。有了雷达以后,英国军队才能够在德军飞机刚上空的同时就在作战室里面马上绘出了整个飞机路线的前进方式,而且马上可以给指令说在你们的防区升空,因为那边马上有敌机。
其实在军事上实也有类似的原则,一个航母编队最大的能力边界不在航母本身。
战机的能力制约了整个航母编队的能力,所以如果大家 数据能够赋能自己的团队,快速做迭代的话,一线的产品同学每天在做假设验证功能时,他能否尽快的拿到洞察结果。
很多团队很难提升迭代决策质量的很重要原因,就是一线团队没有被赋能数据洞察能力,不能高效基于证据的进行试验。
但如果大量产品决策没有这一步的话,所有的假设其实是 是可以被挑战的, 因为没有科学的前提。
前提就需要整个企业形成数据领导力的组织和流程,充分利用定性和定量的数据,做正确的解读,避免创始人的决策质量成为整个企业的决策天花板。
创业中的经营影响因素
我在跟很多投资机构合作时候,他们和我提到最小经营单位,比如说连锁品牌或者C端产品有单店模型或单用户模型。
如果你要参与这种给投资方写报告的项目,就必须提供单用户模型,LTV多少,ARPU多少,获客成本多少,然后边际 际效益多少。
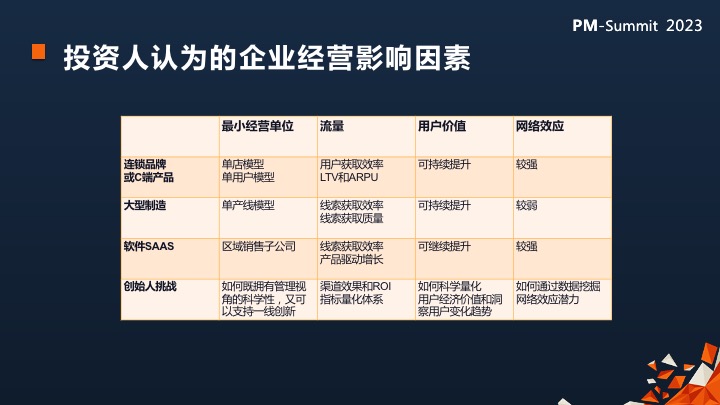
站在投资方角度来看的话,都会以这个逻辑来来看待这个公司的业务。
所以在拆解最小经营单位的时候,就会计算流量成本,用户价值和网络效应。
关键的对于创始人来,其实要计算出自己企业的指标量化体系,理解一个业务阶段指标和指标之间的倍数关系。
比方说对于利润,拉新和留存之间的系数多少。如果一个团队对转化率这种指标重点观察的化,是没有意义的。
很简单,分子分母同时长转化率变吗?同时跌转化率变吗?这种可以反来复去算的循环比率的指标少看。
重复一下:拿利润来看,能把拉新订单活跃算上系数这是王道。
为什么?
因为这个直接可以对应利润把拉新、活跃、订单、留存等的等价关系搞明白,也同时知道了投入和产出,有利于企业决策资源用来看什么更好。
因为每个指标下面都带着一堆的产品需求和渠道成本、货物成本。
当然我在PPT里是简化的,一个公司的整个指标可能很多,么大家能不能做出一个很长的公式,把你们公司里面重要的指标都能做等量关系的折算。
这样在谈到NPS提高50%的时候,我们就知道是否应该奖励客服团队了。
如果一个公司在开管理决策会的时候,会有专人去讨论这个问题,就是这家公司具备数据战略文化和决策科学了,因为这个做法深深嵌入在这个企业的决策流程里了
具体做法可以参考:一把手如何规划企业指标体系。
避免追逐名流
我给大家推荐一本书,”历史中的英雄“。

1943年就出版,悉尼胡克写的一本书,里面讲过就是很多历史名人并没有真正的推动过任何历史的进程,只是有名而已。
用这个思考的原则,大家如果在产品策略里的话,我们要小心跟随性偏见。
这个图上的人,你告诉我哪个人更大一点,再举个例子 如果给你一个增长曲线,2万用户是最大值,如果把它的最大值调成200万的话,那个曲线还是这样吗?
所以为什么我说平时天天看报表,再多的饼图曲线图折线图都会有问题,因为我们会陷入到我们对于数据理解的下降问题.
特别是当老板说”我看完之后我觉得这样的时候”, 小心他也有可能犯一个名人效应的决失误.

那么我们怎么科学的解决问题,我相信这就跟今天的主题有关了,这个步骤是是我们在迈向AI之前首先需要做好的,就是认真应用相关性结论,然后再通过AI提升因果解释能力。
无论是营销、AB测试、还是生产系统里,总之先把这一步数据驱动洞察做好,而不是停留在传统的报表。
因为报表的解读依然具有巨大的偏见经验的影响,我在看这个数的时候一定会脑补上我对这个数的解释,因为人类特别喜欢解释。
比方我问你为什么喜欢穿黑色衣服,然后你立马就说 “我小时候我妈带我去买衣服都买黑色的,所以我喜欢黑色衣服“。
人类大脑的保护机制导致我们会不断的给自己找一个 自圆其说的理由,来解释我们给别人的一个印象。
这是人脑机制不可避免的生物学问题,所以我们要小心这个问题,所以我们需要避免陷入到这种可视化的误区里面,借助相关性来辅助我们做出科学的决策。
这也是数据领导力和决策科学的魅力。